Heres integrates generative models, particularly LLMs (Large Language Models), into its product to design advanced Conversational AI solutions.
This is made possible by a hybrid NLU-LLM approach and by the use of RAG (Retrieval-Augmented Generation) techniques, which enable optimal management of the conversational experience and allow the creative power of the generalist AI model (foundation model) to be applied to the Client’s specific knowledge domain.
Model selection: a tailor-made approach
The Heres product allows integration with any LLM on the market that exposes APIs: depending on the peculiarities of the project and the specific needs of the customer, it is then possible to choose whether to integrate with GPT (via OpenAI or Microsoft), Google Gemini, Claude or any other model. The Heres infrastructure also allows the integrated model to be replaced or multiple models to be used on the same agent. This makes it easy to manage issues related to model obsolescence by always integrating state-of-the-art technologies.
Controlling the Knowledge Base: RAG techniques
Retrieval-Augmented Generation (RAG) is a set of techniques based on the use of LLMs with generalist knowledge combined with the Client’s specialized domain knowledge to orchestrate conversational logics and generate responses. By using this methodology, considerable control can be exercised over the responses generated, reducing the rate of hallucinations extremely significantly.
The Heres infrastructure allows both to manage the Retrieval phase with a “traditional” integration (e.g. API call to the search engine of the Customer’s site) and through semantic search on a vector database. In the latter case, Heres takes care of the creation and maintenance of the vector database, thanks to a dedicated infrastructure based on Open Source solutions such as LLama Index.
The following diagram represents the operational workflow of a Retrieval-Augmented Generation process:
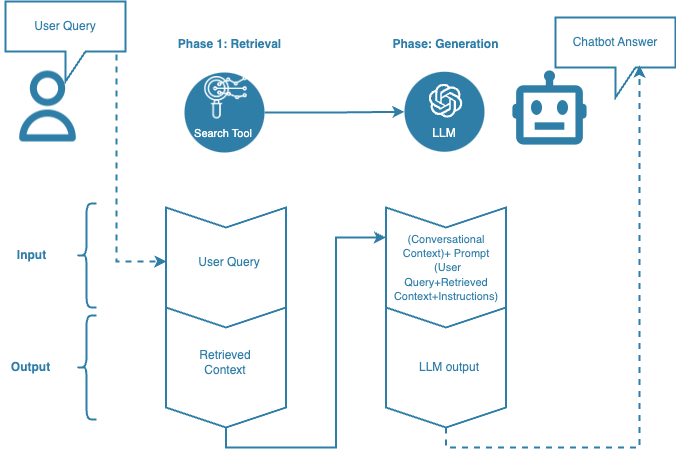
- Search Tool: search tool. In the RAG approach, both existing search tools (e.g., the site’s product search engine) and custom-developed tools can be integrated. In the latter case, the most common approach is to set up a vector database to perform semantic searches.
- LLM: Large Language Model. Generative AI model used for the creation or reworking of textual content. It is the tool that manages the “Generation” phase.
- Retrieval: stage for the retrieval of relevant information (Retrieved Context) from the project Knowledge Base.
- Generation: response generation phase by the LLM, from the output of the Retrieval phase (Retrieved Context), any previous interactions (Conversational Context), the user’s query (User Query), and the instructions provided (Instructions).
- User Query: user question or request.
- Retrieved Context: information retrieved from the project Knowledge Base based on the User Query. The Retrieved Context is the output of the Retrieval phase.
- Conversational Context: set of any previous interactions (prompt+output) in the current conversation with the LLM.
- Prompt: input for the LLM of a single interaction. In the prompt you can include the User Query, the Retrieved Context, and instructions (Instructions) to guide the generation of the response.
- Instructions: part of the prompt where you instruct the LLM on how to handle the User Query using the Retrieved Context.
- LLM Output: output generated by the LLM as a result of a prompt.
- Chatbot Answer: response given by the chatbot to the end user. This response may coincide with the LLM output or may involve some degree of post-processing.